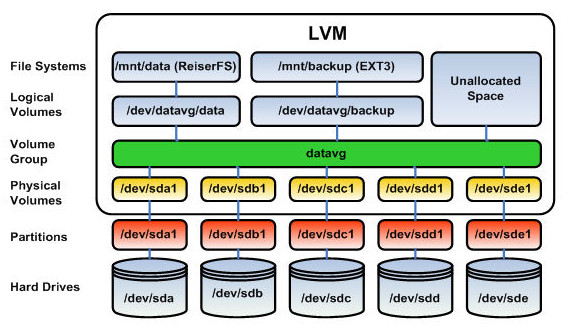
There are some places where the next process is explained , but since I’ve pending an article explaining how to configure Nagios Server with nsca-ng I’ve been thinking in post first an easy steps to configure Nagios from scratch. This document describes how to install Nagios Core, Plugins, NRPE from source on Debian 8.
Prerequisites
$ sudo apt-get install wget build-essential apache2 php5 php5-gd libgd-dev unzip postfix $ sudo wget https://github.com/NagiosEnterprises/nrpe/archive/3.0.tar.gz $ sudo wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.2.0.tar.gz $ sudo wget http://nagios-plugins.org/download/nagios-plugins-2.1.2.tar.gz
Users & Group
$ useradd nagios $ groupadd nagcmd $ usermod -a -G nagios,nagcmd www-data
Nagios Core Installation
$ tar zxvf nagios-4.2.0.tar.gz
$ tar zxvf nagios-plugins-2.1.2.tar.gz
$ cd nagios-4.2.0
$ ./configure --with-command-group=nagcmd --with-httpd-conf=/etc/apache2/ $ make all $ make install $ make install-init $ make install-config $ make install-commandmode $ make install-webconf $ cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/ $ chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
Check Installation
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg Nagios Core 4.2.0 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 08-01-2016 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 8 services. Checked 1 hosts. Checked 1 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 24 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 1 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0
Configure apache2
Enable rewrite and cgi modules
$ sudo a2enmod rewrite && sudo a2enmod cgi
Copy httpd Template Virtual Host
$ sudo cp sample-config/httpd.conf /etc/apache2/sites-available/nagios4.conf
$ sudo chmod 644 /etc/apache2/sites-available/nagios4.conf
Enable Virtual Host
$ sudo a2ensite nagios
Create user nagiosadmin for web interface
$ sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
New password:
Re-type new password:
Adding password for user nagiosadmin
Restart Apache
$ systemctl restart apache2
Install Nagios Plugins
$ cd nagios-plugins-2.1.2/
$ make
$ make install
Enable & Start Nagios
$ systemctl enable nagios Created symlink from /etc/systemd/system/multi-user.target.wants/nagios.service to /etc/systemd/system/nagios.service. $ systemctl start nagios $ systemctl status nagios ● nagios.service - Nagios Loaded: loaded (/etc/systemd/system/nagios.service; enabled) Active: active (running) since Fri 2016-08-19 16:50:47 CEST; 23s ago Main PID: 21272 (nagios) CGroup: /system.slice/nagios.service ├─21272 /usr/local/nagios/bin/nagios /usr/local/nagios/etc/nagios.cfg ├─21273 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21274 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21275 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21276 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh └─21277 /usr/local/nagios/bin/nagios /usr/local/nagios/etc/nagios.cfg Aug 19 16:50:47 cervell nagios[21272]: nerd: Fully initialized and ready to rock! Aug 19 16:50:47 cervell nagios[21272]: wproc: Successfully registered manager as @wproc with query handler Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21276;pid=21276 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21274;pid=21274 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21273;pid=21273 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21275;pid=21275 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21273;pid=21273 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21275;pid=21275 Aug 19 16:50:48 cervell nagios[21272]: Successfully launched command file worker with pid 21277 Aug 19 16:50:48 cervell nagios[21272]: Successfully launched command file worker with pid 21277
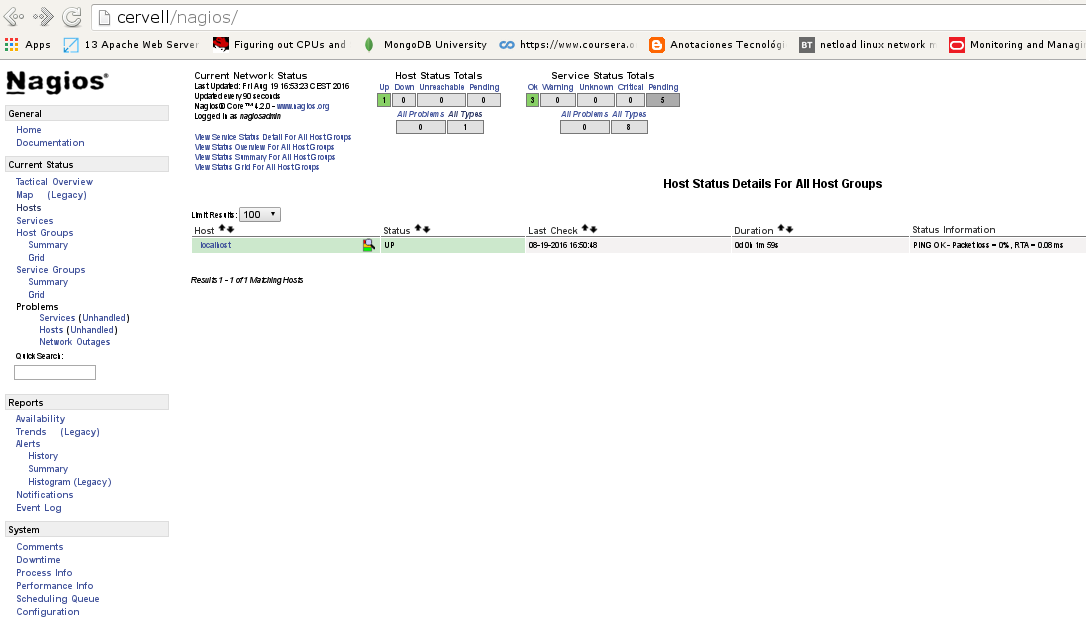
Login to the web interface
NRPE
Install NRPE (Server service)
$ sudo apt-get install libssl-dev
$ tar zxvf nrpe-3.0.tar.gz
$ cd nrpe-3.0/
$ ./configure
$ make all
$ make install
Create NRPE service (systemd)
$ make install-init
Create NRPE service (systemd) Manual
service code
$ vi /etc/systemd/system/nrpe.service [Unit] Description=NRPE After=nagios.service [Install] WantedBy=multi-user.target [Service] Type=simple PIDFile=/usr/local/nagios/var/nrpe.pid User=nagios Group=nagios ExecStart=/usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d ExecStop=/usr/bin/killall /usr/local/nagios/bin/nrpe
Enable NRPE service
$ systemctl enable nrpe
Created symlink from /etc/systemd/system/multi-user.target.wants/nrpe.service to /etc/systemd/system/nrpe.service.
Start service
$ systemctl start nrpe
Check status
$ systemctl status nrpe ● nrpe.service - NRPE Loaded: loaded (/etc/systemd/system/nrpe.service; enabled) Active: active (running) since Mon 2016-08-22 15:48:12 CEST; 8s ago Main PID: 26435 (nrpe) CGroup: /system.slice/nrpe.service └─26435 /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d Aug 22 15:48:12 cervell nrpe[26435]: Starting up daemon Aug 22 15:48:12 cervell nrpe[26435]: Server listening on 0.0.0.0 port 5666. Aug 22 15:48:12 cervell nrpe[26435]: Server listening on :: port 5666. Aug 22 15:48:12 cervell nrpe[26435]: Listening for connections on port 5666 Aug 22 15:48:12 cervell nrpe[26435]: Allowing connections from: 127.0.0.1
Add NRPE on /usr/local/nagios/etc/objectsi/commands.cfg
define command{ command_name check_nrpe command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ }
Config files (For new client)
vi /usr/local/nagios/etc/objects/contacts.cfg
define contact{ contact_name nagiosadmin ; Short name of user use generic-contact ; Inherit default values from generic-contact template (defined above) alias Nagios Admin ; Full name of user email nagiosadmin@whatever.com ; ## <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ****** } define contactgroup{ contactgroup_name admins alias Nagios Administrators members nagiosadmin }
vi /usr/local/nagios/etc/objects/host-service-definitions.cfg
define host{ name Host-krbulan ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** use generic-host check_period 24x7 check_interval 5 retry_interval 1 max_check_attempts 10 check_command check-host-alive notification_period workhours notification_interval 30 notification_options d,u,r contact_groups admins register 0 } define service{ name Service-krbulan ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** active_checks_enabled 1 passive_checks_enabled 1 parallelize_check 1 obsess_over_service 1 check_freshness 0 notifications_enabled 1 event_handler_enabled 1 flap_detection_enabled 1 process_perf_data 1 retain_status_information 1 retain_nonstatus_information 1 is_volatile 0 check_period 24x7 max_check_attempts 3 normal_check_interval 3 retry_check_interval 2 contact_groups admins notification_options w,u,c,r notification_interval 60 notification_period 24x7 register 0 }
vi /usr/local/nagios/etc/objects/hostgroup.cfg
define hostgroup { hostgroup_name Krbulan-Servers ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** alias Servidors Krbu CPD members wopr }
vi /usr/local/nagios/etc/objects/wopr.cfg # This client name is wopr, you can change this with your client name
define host{ use Host-krbulan ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN host-service-definitions.cfg ****** host_name wopr hostgroups Krbulan-Servers ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN hostgroup.cfg ****** alias wopr address 192.168.1.10 ## <<***** CHANGE THIS WITH YOUR IP ****** } define service{ use Service-krbulan ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN hostgroup.cfg ****** host_name wopr service_description Current Load check_command check_nrpe!check_load } define service{ use Service-krbulan host_name wopr service_description Total Processes check_command check_nrpe!check_total_procs } define service { use Service-krbulan host_name wopr service_description Memoria check_command check_nrpe!check_memory }