One of the methods of error reporting with DRLM is nsca-ng, there is a sample configuration on http://docs.drlm.org/en/latest/ErrorReporting.html . In this document we cover the configuration Nagios Server with nsca-ng and also DRLM Server configuration to monitor errors from DRLM Server when running backups.
Of course we assume you have a Nagios Server configured and a DRLM Server
if not, don’t worry, just take a look on the next links
How to install DRLM
How to install NAGIOS
DRLM Server configuration
Install nsca-ng-client package
$ apt install nsca-ng-client
Set up config files
At least 2 files must be configured, in thes example we’re using 3, default.conf has the default values that can be overwritten in local.conf
/usr/share/drlm/conf/default.conf
# REPORT_TYPE=nagios # NAGIOS VARIABLES # # These are default values and can be overwritten in local.conf according to your NAGIOS installation and configuration. # NAGCMD="/usr/sbin/send_nsca" NAGSVC="DRLM" NAGHOST="$HOSTNAME" NAGCONF="/etc/drlm/alerts/nagios.cfg"
Note
Keep an eye on this variable NAGSVC . We’re going to use it on the Nagios server side as a service description it must match.
/etc/drlm/local.conf
NAGSVC="DRLM_Backup"
Note
As you can see this varible was defined previously on default.conf , it is just to show you than it can be overwritten with the /etc/drlm/local.conf file, so if you want, you can dismiss this step.
/etc/drlm/alerts/nagios.cfg
#### DRLM (Disaster Recovery Linux Manager) Nagios error reporting sample configuration file. #### Default: /etc/drlm/alerts/nagios.cfg ### identity = <string> # Send the specified client identity to the server. # By default, localhost will be used. identity = "DRLM" ### server = <string> # Connect and talk to the specified server address or hostname. # The default server is "localhost". server = "Cervell" ### port = <string> # Connect to the specified service name or port number on the # server instead of using the default port (5668). port = 5668 password = "change-me"
Where:
- DRLM: Is the name of the DRLM Server
- Cervell: Is the name of the Nagios Server
- port: Is the port where the Nagios Server is listening
- password: Is the default password on the nsca-ng-server
Nagios Server configuration
Once the DRLM Server has been configured we’ll set up the Nagios Server.
Install required packages
$ apt install nsca-ng-server
Set up nsca-ng config files
/etc/nsca-ng/nsca-ng.cfg
command_file = "/usr/local/nagios/var/rw/nagios.cmd" listen = "Cervell" # only listen on localhost. If you use systemd this # this option is overriden by the # nsca-ng-server.socket file. user = "nagios" # run as user nagios pid_file = "/var/run/nsca-ng/nsca-ng.pid" # pid file for nsca-ng include(/etc/nsca-ng/nsca-ng.local.cfg) authorize "*" { password = "change-me" # # The original NSCA server permits all authenticated clients to submit # arbitrary check results. To get this behaviour, enable the following # lines: # hosts = ".*" services = ".*" }
Note
This config file has been reduced to only the minimum requirements , if you want to see all options check the original file /etc/nsca-ng/nsca-ng.cfg
/lib/systemd/system/nsca-ng-server.socket
[Unit] Description=NSCA-ng Socket Documentation=man:nsca-ng(8) man:nsca-ng.cfg(5) [Socket] ListenStream=5668 #BindIPv6Only=both [Install] WantedBy=sockets.target
Start nsca-ng-server service
$ systemctl start nsca-ng-server
- Check the status of the service
$ systemctl status nsca-ng-server ● nsca-ng-server.service - Monitoring Command Acceptor Loaded: loaded (/lib/systemd/system/nsca-ng-server.service; static) Active: active (running) since Fri 2017-02-17 18:35:46 CET; 5s ago Docs: man:nsca-ng(8) man:nsca-ng.cfg(5) Main PID: 14495 (nsca-ng) CGroup: /system.slice/nsca-ng-server.service └─14495 /usr/sbin/nsca-ng -c /etc/nsca-ng/nsca-ng.cfg Feb 17 18:35:46 cervell nsca-ng[14495]: Ignoring `-b'/`listen' when socket activated Feb 17 18:35:46 cervell nsca-ng[14495]: nsca-ng 1.4 (OpenSSL 1.0.1t, libev 4.15 with epoll) starting up
Nagios Config files
For this kind of configuration we’re using passive checks, the error notification is set for a limited time using the variable freshness_threshold. It’s importatnt to setup the notifications in order to receibe an email in case of error , if not you could miss it.
- Add a new service on
/usr/local/nagios/etc/objects/templates.cfg
define service{ name passive_service active_checks_enabled 0 passive_checks_enabled 1 # We want only passive checking flap_detection_enabled 0 register 0 # This is a template, not a real service is_volatile 0 check_period 24x7 max_check_attempts 1 normal_check_interval 5 retry_check_interval 1 check_freshness 1 freshness_threshold 600 contact_groups admins check_command check_dummy!0 notifications_enabled 1 ; Service notifications are enabled notification_interval 10 notification_period 24x7 notification_options w,u,c,r stalking_options w,c,u }
- Add the DRLM Server on a hostgroup
/usr/local/nagios/etc/object/hostgroup.cfg
define hostgroup { hostgroup_name Krbulan-Servers alias Servidors Test members DRLM }
- Add a new check
/usr/local/nagios/etc/object/commands.cfg
#NSCA-ng Command define command{ command_name check_dummy command_line $USER1$/check_dummy $ARG1$ }
- Define the host and service
/usr/local/nagios/etc/object/DRLM.cfg
define host{ use Host-krbulan host_name DRLM hostgroups Krbulan-Servers alias DRLM address 192.168.7.9 } define service{ use passive_service service_description DRLM_Backup host_name DRLM notifications_enabled 1 }
Warning
service_description has to match with the variable NAGSVC before configured on the DRLM server.
- Check Nagios configuration files
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg Nagios Core 4.2.0 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 08-01-2016 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 16 services. Checked 3 hosts. Checked 2 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 26 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 3 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
Testing the configuration
From DRLM server exec runbackup (dummy server is not online)
$ root@DRLM:~# drlm -vD runbackup -c dummy Disaster Recovery Linux Manager 2.1.0 / Git Using log file: /var/log/drlm/drlm-DRLM-runbackup.20170217.190926.log ERROR: drlm:runbackup: Client dummy SSH Server is not available (SSH) aborting ... Aborting due to an error, check /var/log/drlm/drlm-DRLM-runbackup.20170217.190926.log for details Terminated
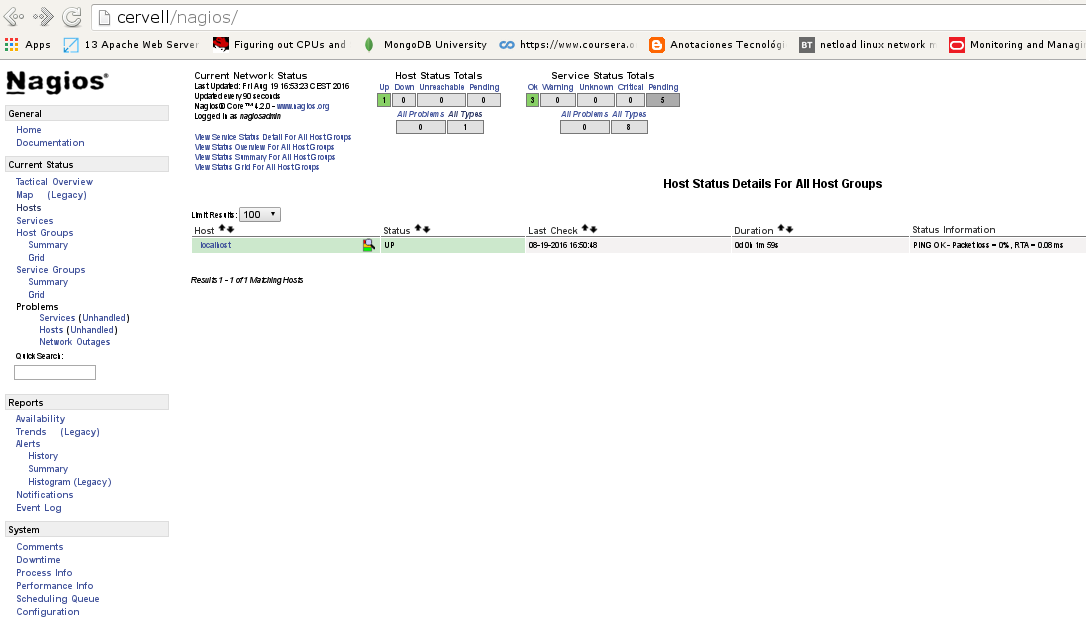
On Nagios
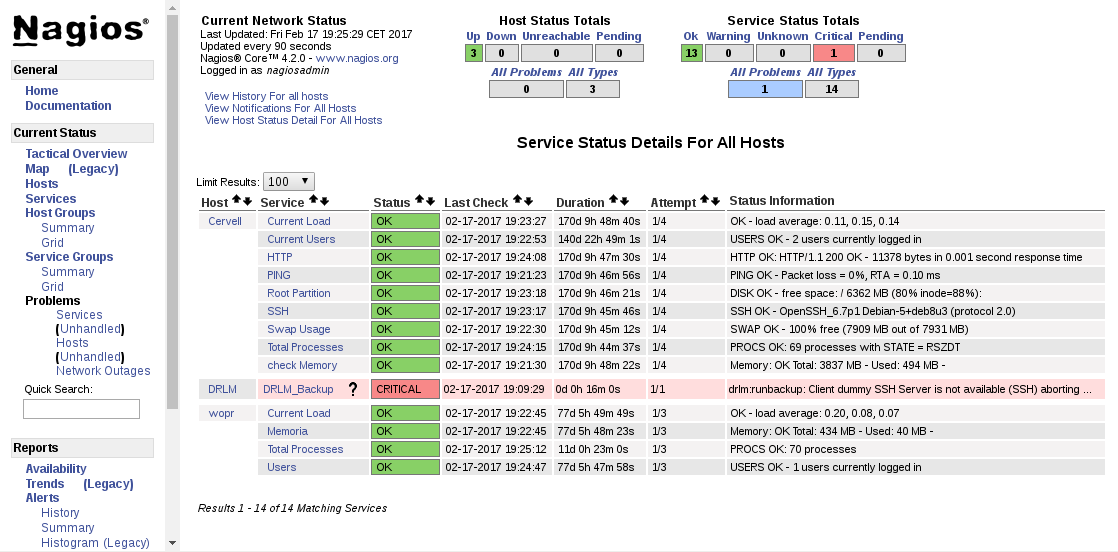
On the notifications we see that the mail has been send
![]()