
De les empreses que han patit una important pèrdua de dades, un 43% mai torna a obrir, mentre que un 29% tanca al cap de dos anys [1]. Els sistemes informàtics són cada vegada més crítics i una aturada dels serveis de diverses hores o dies es converteixen directament en pèrdues econòmiques molt importants.
Estudis amb un enfocament més holístic conclouen que per cada 1 € d'inversió en un pla anterior al desastre pot suposar un estalvi de 4 € en la resposta i recuperació en el cas que aquest es produeixi. [2]
La majoria de les petites empreses no tenen un pla de recuperació de desastres i s'estima que el 25% d'aquestes no torna a obrir després d'un desastre major.
Compartim amb vosaltres un interessant article on podreu aprofundir més sobre el tema:
https://digital.com/blog/disaster-proof/#ixzz5FP9KC1Ny
[1] http://www.continuitycentral.com/feature0660.html
[2] http://nws.weather.gov/nthmp/Minutes/oct-nov07/post-disaster_recovery_planning_forum_uo-csc-2.pdf
GNU/LINUX
Setup Nagios Server with
nsca-ng for DRLM
One of the methods of error reporting with DRLM is nsca-ng, there is a sample configuration on http://docs.drlm.org/en/latest/ErrorReporting.html . In this document we cover the configuration Nagios Server with nsca-ng and also DRLM Server configuration to monitor errors from DRLM Server when running backups.
Of course we assume you have a Nagios Server configured and a DRLM Server
if not, don’t worry, just take a look on the next links
How to install DRLM
How to install NAGIOS
DRLM Server configuration
Install nsca-ng-client package
$ apt install nsca-ng-client
Set up config files
At least 2 files must be configured, in thes example we’re using 3, default.conf has the default values that can be overwritten in local.conf
/usr/share/drlm/conf/default.conf
# REPORT_TYPE=nagios # NAGIOS VARIABLES # # These are default values and can be overwritten in local.conf according to your NAGIOS installation and configuration. # NAGCMD="/usr/sbin/send_nsca" NAGSVC="DRLM" NAGHOST="$HOSTNAME" NAGCONF="/etc/drlm/alerts/nagios.cfg"
Note
Keep an eye on this variable NAGSVC . We’re going to use it on the Nagios server side as a service description it must match.
/etc/drlm/local.conf
NAGSVC="DRLM_Backup"
Note
As you can see this varible was defined previously on default.conf , it is just to show you than it can be overwritten with the /etc/drlm/local.conf file, so if you want, you can dismiss this step.
/etc/drlm/alerts/nagios.cfg
#### DRLM (Disaster Recovery Linux Manager) Nagios error reporting sample configuration file. #### Default: /etc/drlm/alerts/nagios.cfg ### identity = <string> # Send the specified client identity to the server. # By default, localhost will be used. identity = "DRLM" ### server = <string> # Connect and talk to the specified server address or hostname. # The default server is "localhost". server = "Cervell" ### port = <string> # Connect to the specified service name or port number on the # server instead of using the default port (5668). port = 5668 password = "change-me"
Where:
- DRLM: Is the name of the DRLM Server
- Cervell: Is the name of the Nagios Server
- port: Is the port where the Nagios Server is listening
- password: Is the default password on the nsca-ng-server
Nagios Server configuration
Once the DRLM Server has been configured we’ll set up the Nagios Server.
Install required packages
$ apt install nsca-ng-server
Set up nsca-ng config files
/etc/nsca-ng/nsca-ng.cfg
command_file = "/usr/local/nagios/var/rw/nagios.cmd" listen = "Cervell" # only listen on localhost. If you use systemd this # this option is overriden by the # nsca-ng-server.socket file. user = "nagios" # run as user nagios pid_file = "/var/run/nsca-ng/nsca-ng.pid" # pid file for nsca-ng include(/etc/nsca-ng/nsca-ng.local.cfg) authorize "*" { password = "change-me" # # The original NSCA server permits all authenticated clients to submit # arbitrary check results. To get this behaviour, enable the following # lines: # hosts = ".*" services = ".*" }
Note
This config file has been reduced to only the minimum requirements , if you want to see all options check the original file /etc/nsca-ng/nsca-ng.cfg
/lib/systemd/system/nsca-ng-server.socket
[Unit] Description=NSCA-ng Socket Documentation=man:nsca-ng(8) man:nsca-ng.cfg(5) [Socket] ListenStream=5668 #BindIPv6Only=both [Install] WantedBy=sockets.target
Start nsca-ng-server service
$ systemctl start nsca-ng-server
- Check the status of the service
$ systemctl status nsca-ng-server ● nsca-ng-server.service - Monitoring Command Acceptor Loaded: loaded (/lib/systemd/system/nsca-ng-server.service; static) Active: active (running) since Fri 2017-02-17 18:35:46 CET; 5s ago Docs: man:nsca-ng(8) man:nsca-ng.cfg(5) Main PID: 14495 (nsca-ng) CGroup: /system.slice/nsca-ng-server.service └─14495 /usr/sbin/nsca-ng -c /etc/nsca-ng/nsca-ng.cfg Feb 17 18:35:46 cervell nsca-ng[14495]: Ignoring `-b'/`listen' when socket activated Feb 17 18:35:46 cervell nsca-ng[14495]: nsca-ng 1.4 (OpenSSL 1.0.1t, libev 4.15 with epoll) starting up
Nagios Config files
For this kind of configuration we’re using passive checks, the error notification is set for a limited time using the variable freshness_threshold. It’s importatnt to setup the notifications in order to receibe an email in case of error , if not you could miss it.
- Add a new service on
/usr/local/nagios/etc/objects/templates.cfg
define service{ name passive_service active_checks_enabled 0 passive_checks_enabled 1 # We want only passive checking flap_detection_enabled 0 register 0 # This is a template, not a real service is_volatile 0 check_period 24x7 max_check_attempts 1 normal_check_interval 5 retry_check_interval 1 check_freshness 1 freshness_threshold 600 contact_groups admins check_command check_dummy!0 notifications_enabled 1 ; Service notifications are enabled notification_interval 10 notification_period 24x7 notification_options w,u,c,r stalking_options w,c,u }
- Add the DRLM Server on a hostgroup
/usr/local/nagios/etc/object/hostgroup.cfg
define hostgroup { hostgroup_name Krbulan-Servers alias Servidors Test members DRLM }
- Add a new check
/usr/local/nagios/etc/object/commands.cfg
#NSCA-ng Command define command{ command_name check_dummy command_line $USER1$/check_dummy $ARG1$ }
- Define the host and service
/usr/local/nagios/etc/object/DRLM.cfg
define host{ use Host-krbulan host_name DRLM hostgroups Krbulan-Servers alias DRLM address 192.168.7.9 } define service{ use passive_service service_description DRLM_Backup host_name DRLM notifications_enabled 1 }
Warning
service_description has to match with the variable NAGSVC before configured on the DRLM server.
- Check Nagios configuration files
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg Nagios Core 4.2.0 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 08-01-2016 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 16 services. Checked 3 hosts. Checked 2 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 26 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 3 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0 Things look okay - No serious problems were detected during the pre-flight check
Testing the configuration
From DRLM server exec runbackup (dummy server is not online)
$ root@DRLM:~# drlm -vD runbackup -c dummy Disaster Recovery Linux Manager 2.1.0 / Git Using log file: /var/log/drlm/drlm-DRLM-runbackup.20170217.190926.log ERROR: drlm:runbackup: Client dummy SSH Server is not available (SSH) aborting ... Aborting due to an error, check /var/log/drlm/drlm-DRLM-runbackup.20170217.190926.log for details Terminated
On Nagios
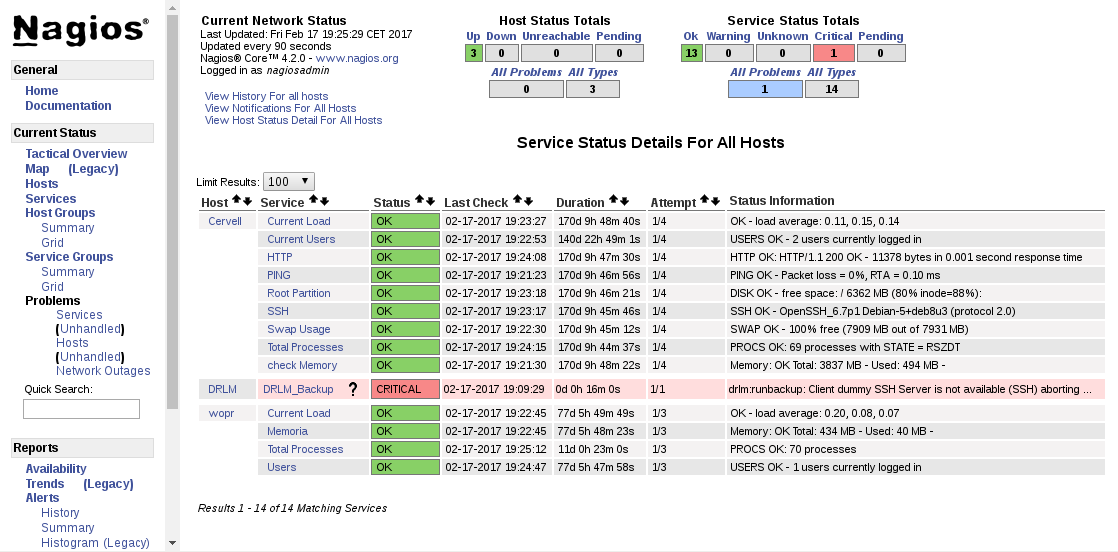
On the notifications we see that the mail has been send
![]()
How to install Nagios 4.2.0 (Debian 8)
There are some places where the next process is explained , but since I’ve pending an article explaining how to configure Nagios Server with nsca-ng I’ve been thinking in post first an easy steps to configure Nagios from scratch. This document describes how to install Nagios Core, Plugins, NRPE from source on Debian 8.
Prerequisites
$ sudo apt-get install wget build-essential apache2 php5 php5-gd libgd-dev unzip postfix $ sudo wget https://github.com/NagiosEnterprises/nrpe/archive/3.0.tar.gz $ sudo wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.2.0.tar.gz $ sudo wget http://nagios-plugins.org/download/nagios-plugins-2.1.2.tar.gz
Users & Group
$ useradd nagios $ groupadd nagcmd $ usermod -a -G nagios,nagcmd www-data
Nagios Core Installation
$ tar zxvf nagios-4.2.0.tar.gz
$ tar zxvf nagios-plugins-2.1.2.tar.gz
$ cd nagios-4.2.0
$ ./configure --with-command-group=nagcmd --with-httpd-conf=/etc/apache2/ $ make all $ make install $ make install-init $ make install-config $ make install-commandmode $ make install-webconf $ cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/ $ chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
Check Installation
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg Nagios Core 4.2.0 Copyright (c) 2009-present Nagios Core Development Team and Community Contributors Copyright (c) 1999-2009 Ethan Galstad Last Modified: 08-01-2016 License: GPL Website: https://www.nagios.org Reading configuration data... Read main config file okay... Read object config files okay... Running pre-flight check on configuration data... Checking objects... Checked 8 services. Checked 1 hosts. Checked 1 host groups. Checked 0 service groups. Checked 1 contacts. Checked 1 contact groups. Checked 24 commands. Checked 5 time periods. Checked 0 host escalations. Checked 0 service escalations. Checking for circular paths... Checked 1 hosts Checked 0 service dependencies Checked 0 host dependencies Checked 5 timeperiods Checking global event handlers... Checking obsessive compulsive processor commands... Checking misc settings... Total Warnings: 0 Total Errors: 0
Configure apache2
Enable rewrite and cgi modules
$ sudo a2enmod rewrite && sudo a2enmod cgi
Copy httpd Template Virtual Host
$ sudo cp sample-config/httpd.conf /etc/apache2/sites-available/nagios4.conf
$ sudo chmod 644 /etc/apache2/sites-available/nagios4.conf
Enable Virtual Host
$ sudo a2ensite nagios
Create user nagiosadmin for web interface
$ sudo htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin
New password:
Re-type new password:
Adding password for user nagiosadmin
Restart Apache
$ systemctl restart apache2
Install Nagios Plugins
$ cd nagios-plugins-2.1.2/
$ make
$ make install
Enable & Start Nagios
$ systemctl enable nagios Created symlink from /etc/systemd/system/multi-user.target.wants/nagios.service to /etc/systemd/system/nagios.service. $ systemctl start nagios $ systemctl status nagios ● nagios.service - Nagios Loaded: loaded (/etc/systemd/system/nagios.service; enabled) Active: active (running) since Fri 2016-08-19 16:50:47 CEST; 23s ago Main PID: 21272 (nagios) CGroup: /system.slice/nagios.service ├─21272 /usr/local/nagios/bin/nagios /usr/local/nagios/etc/nagios.cfg ├─21273 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21274 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21275 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh ├─21276 /usr/local/nagios/bin/nagios --worker /usr/local/nagios/var/rw/nagios.qh └─21277 /usr/local/nagios/bin/nagios /usr/local/nagios/etc/nagios.cfg Aug 19 16:50:47 cervell nagios[21272]: nerd: Fully initialized and ready to rock! Aug 19 16:50:47 cervell nagios[21272]: wproc: Successfully registered manager as @wproc with query handler Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21276;pid=21276 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21274;pid=21274 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21273;pid=21273 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21275;pid=21275 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21273;pid=21273 Aug 19 16:50:47 cervell nagios[21272]: wproc: Registry request: name=Core Worker 21275;pid=21275 Aug 19 16:50:48 cervell nagios[21272]: Successfully launched command file worker with pid 21277 Aug 19 16:50:48 cervell nagios[21272]: Successfully launched command file worker with pid 21277
Login to the web interface
NRPE
Install NRPE (Server service)
$ sudo apt-get install libssl-dev
$ tar zxvf nrpe-3.0.tar.gz
$ cd nrpe-3.0/
$ ./configure
$ make all
$ make install
Create NRPE service (systemd)
$ make install-init
Create NRPE service (systemd) Manual
service code
$ vi /etc/systemd/system/nrpe.service [Unit] Description=NRPE After=nagios.service [Install] WantedBy=multi-user.target [Service] Type=simple PIDFile=/usr/local/nagios/var/nrpe.pid User=nagios Group=nagios ExecStart=/usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d ExecStop=/usr/bin/killall /usr/local/nagios/bin/nrpe
Enable NRPE service
$ systemctl enable nrpe
Created symlink from /etc/systemd/system/multi-user.target.wants/nrpe.service to /etc/systemd/system/nrpe.service.
Start service
$ systemctl start nrpe
Check status
$ systemctl status nrpe ● nrpe.service - NRPE Loaded: loaded (/etc/systemd/system/nrpe.service; enabled) Active: active (running) since Mon 2016-08-22 15:48:12 CEST; 8s ago Main PID: 26435 (nrpe) CGroup: /system.slice/nrpe.service └─26435 /usr/local/nagios/bin/nrpe -c /usr/local/nagios/etc/nrpe.cfg -d Aug 22 15:48:12 cervell nrpe[26435]: Starting up daemon Aug 22 15:48:12 cervell nrpe[26435]: Server listening on 0.0.0.0 port 5666. Aug 22 15:48:12 cervell nrpe[26435]: Server listening on :: port 5666. Aug 22 15:48:12 cervell nrpe[26435]: Listening for connections on port 5666 Aug 22 15:48:12 cervell nrpe[26435]: Allowing connections from: 127.0.0.1
Add NRPE on /usr/local/nagios/etc/objectsi/commands.cfg
define command{ command_name check_nrpe command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -c $ARG1$ }
Config files (For new client)
vi /usr/local/nagios/etc/objects/contacts.cfg
define contact{ contact_name nagiosadmin ; Short name of user use generic-contact ; Inherit default values from generic-contact template (defined above) alias Nagios Admin ; Full name of user email nagiosadmin@whatever.com ; ## <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ****** } define contactgroup{ contactgroup_name admins alias Nagios Administrators members nagiosadmin }
vi /usr/local/nagios/etc/objects/host-service-definitions.cfg
define host{ name Host-krbulan ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** use generic-host check_period 24x7 check_interval 5 retry_interval 1 max_check_attempts 10 check_command check-host-alive notification_period workhours notification_interval 30 notification_options d,u,r contact_groups admins register 0 } define service{ name Service-krbulan ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** active_checks_enabled 1 passive_checks_enabled 1 parallelize_check 1 obsess_over_service 1 check_freshness 0 notifications_enabled 1 event_handler_enabled 1 flap_detection_enabled 1 process_perf_data 1 retain_status_information 1 retain_nonstatus_information 1 is_volatile 0 check_period 24x7 max_check_attempts 3 normal_check_interval 3 retry_check_interval 2 contact_groups admins notification_options w,u,c,r notification_interval 60 notification_period 24x7 register 0 }
vi /usr/local/nagios/etc/objects/hostgroup.cfg
define hostgroup { hostgroup_name Krbulan-Servers ## <<***** CHANGE THIS WITH YOUR PREFERED NAME ****** alias Servidors Krbu CPD members wopr }
vi /usr/local/nagios/etc/objects/wopr.cfg # This client name is wopr, you can change this with your client name
define host{ use Host-krbulan ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN host-service-definitions.cfg ****** host_name wopr hostgroups Krbulan-Servers ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN hostgroup.cfg ****** alias wopr address 192.168.1.10 ## <<***** CHANGE THIS WITH YOUR IP ****** } define service{ use Service-krbulan ## <<***** CHANGE THIS WITH YOUR NAME DEFINED IN hostgroup.cfg ****** host_name wopr service_description Current Load check_command check_nrpe!check_load } define service{ use Service-krbulan host_name wopr service_description Total Processes check_command check_nrpe!check_total_procs } define service { use Service-krbulan host_name wopr service_description Memoria check_command check_nrpe!check_memory }
Configuration of Oracle ASMlib disks in GNU/Linux
ASMLib is a support library for the Automatic Storage Management feature of the Oracle Database.
Simplifies database administration and reduces kernel resource usage, but some configurations in the OS disks should be done before ASMlib will work as pretended.
This article will explain the configuration of ASMlib disks in GNU/Linux systems in order to ASM can manage them.
Oracle ASM software should be installed and properly configured previously, see note details.
Note
- ASMlib download page:
- http://www.oracle.com/technetwork/server-storage/linux/asmlib/index-101839.html
- ASMlib base configuration:
- http://www.oracle.com/technetwork/server-storage/linux/install-082632.html
We will configure the following system disks to be used by ASMlib:
| GNU/Linux Device Name | ASM label |
|---|---|
| /dev/mapper/asmdisk_01 | ORA_ASM_DISK01 |
| /dev/mapper/asmdisk_02 | ORA_ASM_DISK02 |
Creating Partitions (any node)
First of all we will partition the disks:
Using fdisk:
$ for i in 01 02; do echo -e "o\nn\np\n1\n\n\nw" | fdisk /dev/mapper/asmdisk_$i; done
Using parted:
$ for i in 01 02; do parted -s -a optimal /dev/mapper/asmdisk_$i mklabel gpt mkpart primary 0% 100%; done
Check parititons (any node)
Now, check if partitions were created correctly.
Using fdisk:
$ for i in 01 02; do fdisk -l /dev/mapper/asmdisk_$i; done ... Device Boot Start End Blocks Id System /dev/mapper/asmdisk_01p1 1 104433 838858041 83 Linux ... Device Boot Start End Blocks Id System /dev/mapper/asmdisk_02p1 1 26108 209712478+ 83 Linux
Using parted:
$ for i in 01 02; do parted /dev/mapper/asmdisk_$i print; done ... Disk /dev/mapper/asmdisk_01: 85900MB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 1049kB 85.9GB 85.9GB primary ... Disk /dev/mapper/asmdisk_02: 85900MB Sector size (logical/physical): 512B/512B Partition Table: gpt Number Start End Size File system Name Flags 1 1049kB 85.9GB 85.9GB primary
Load partitons (all nodes)
The partitions must be loaded on all node’s kernel to properly label them with ASMlib.
$ for i in 01 02; do kpartx -a /dev/mapper/asmdisk_$i; done
Check loaded parts (all nodes)
$ for i in 01 02; do kpartx -l /dev/mapper/asmdisk_$i; done asmdisk_01p1 : 0 1677716082 /dev/mapper/asmdisk_01 63 asmdisk_02p1 : 0 419424957 /dev/mapper/asmdisk_02 63
Label ASM disks (any node)
If partitions were loaded correctly in all nodes, we will label the partitions in ASMlib:
$ for i in 01 02; do /etc/init.d/oracleasm createdisk ORA_ASM_DISK${i} /dev/mapper/asmdisk_${i}p1; done Marking disk "ORA_ASM_DISK01" as an ASM disk: [ OK ] Marking disk "ORA_ASM_DISK02" as an ASM disk: [ OK ]
$ oracleasm listdisks ORA_ASM_DISK01 ORA_ASM_DISK02
Scan/List ASM disks (other nodes)
$ oracleasm scandisks Reloading disk partitions: done Cleaning any stale ASM disks... Scanning system for ASM disks... Instantiating disk "ORA_ASM_DISK01" Instantiating disk "ORA_ASM_DISK02"
$ oracleasm listdisks ORA_ASM_DISK01 ORA_ASM_DISK02
Conclusion
Hope this short How-To article will be useful to any GNU/Linux SysAdmin and/or DBA using Oracle ASM with ASMlib.
Brief Introduction to Logical Volume Manager (LVM) – Concept and example of application
What if you suddenly run out of space in your home or root partition and want to use the left space from other HD partitions to get by till you make room or you get another HDD, all this on the fly? What if you want to double your home partition space with a spare HDD? Do you ever feel like you need some kind of mirror of your whole setup or a part of it, so you are prevented against hardware failures?
Logical Volume Manager (LVM) is a great answer to all of these questions. It is a tool implemented in the Linux Kernel that let’s you work with logical volumes (LV from now on), volumes that lay between the physical hard drives and the filesystems that will bring these LV to life. A LV needs to belong to a Virtual Grup (VG) in order to operate, as well as a VG can only exist after a Physical Volume (PV), which is the adaptation of a HDD or HDD partition so it can work with LVs. LVs, on its way, are divided in Physical Extents (PE), and they are the ones that determinate the size of a LV, though it is easily translatable to a human readable value. So, more or less, this is what we have:
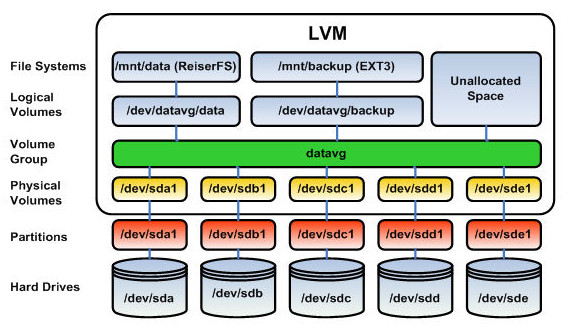
Image source: wikimedia
Initial setup
We created a Centos6 virtual machine environment in order to test the major capabilities of LVM and so we can safely do, undo and redo. Most of the distributions installers are able to work with LVM from the very beginning. We had a ~40GB HDD that we divided this way:
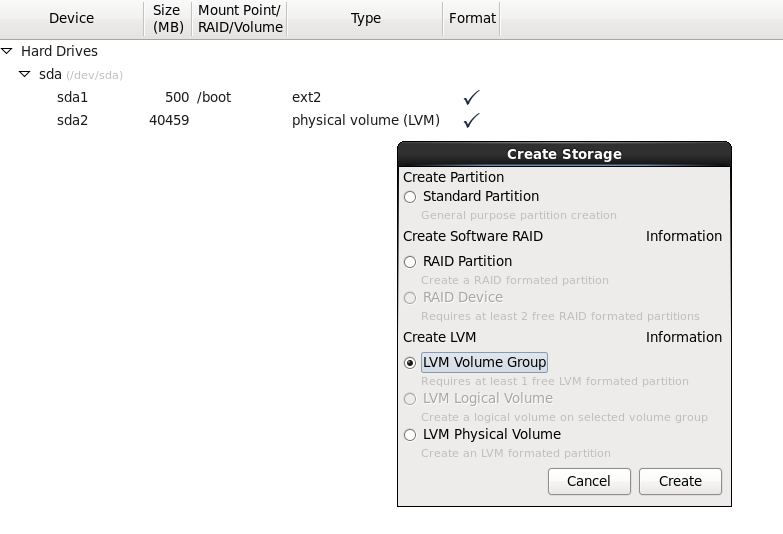
We created a 500MB ext2 /dev/sda1 standard partition that will contain /boot files. It is recommended not to have the boot partition under LVM as there are bootloaders that cannot read this kind of partitions. We then created a PV out of sda2 with the whole remaining HDD space. We made a VG from this PV named vg_centos6 that will separately contain root, var, home and swap partitions:
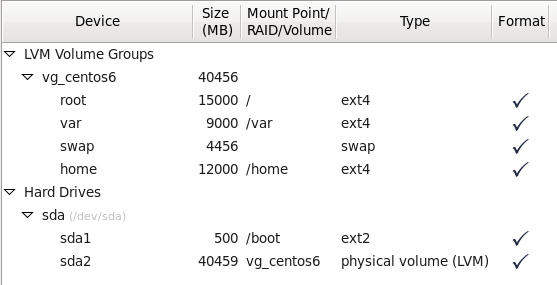
LVM flexibility
If you ever feel lost about any parameter of your LVM configuration, you can always paint it back with these commands:
$ pvs $ vgs $ lvs
The first will display information about PVs, the second about VGs and the third one about LVs. So that’s it! Let’s start playing with our LVM setup. To learn about LVM flexibility, let’s imagine a case where our home partition has no space left and we need to somehow extend it, but we don’t have any spare HDD to attach to our PC.
However, you realize that at some point you gave your swap space much more GB than those actually needed, always there sitting around. Why not moving them to our home partition? This is how we can do it:
First we need to unmount the swap partition:
$ swapoff
We can now reduce the size of the swap LV:
$ lvreduce -L -2G /dev/vg_centos6/swap
With this command we are shrinking our 4,5GB swap LV by 2GB. As so, we have to reformat it to tell it to occupy the new space created:
$ mkswap /dev/vg_centos6/swap
And we activated back:
$ swapon -va
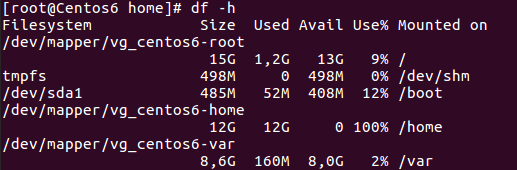
We can tell the swap space reduction by issuing:
$ free -m
So now, as you can imagine, we have 2GB in our VG that are unallocated:

Let’s assign them to our home partition:
$ lvextend -L+2G /dev/vg_centos6/home
Now we have given 2GB of our VG free space to the home LV. However, unless we tell the file system to fit again in the partition, it will continue appearing as full. We can arrange that by:
$ resize2fs /dev/vg_centos6/home
Resulting in:
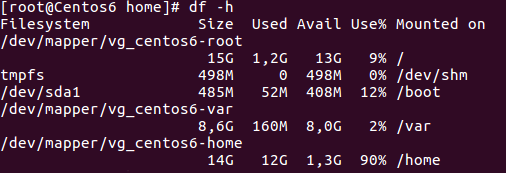
We brought back to life a file system that was at 100%.
Now imagine we want to expand the root LV with an extra HDD you attached to the OS. To do so we will add a raw 40GB HDD to our virtual machine. Let’s give it LVM format:
$ fdisk -cu /dev/sdb
The new partition id will be 8e (Linux LVM) and it will occupy the whole disk. Once written these parameters to the disk, we have to create a PV out of it:
$ pvcreate /dev/sdb1
We now extend our initial VG vg_centos6 with our latest incorporation:
$ vgextend vg_centos6 /dev/sdb1

We now have 40GB in our VG that are free to assign wherever we want. Let’s add 10GB to the root LV:
$ lvextend -L +10G /dev/vg_centos6/root
Again, we have to issue resize2fs so the file system recognizes the new added space:
$ resize2fs /dev/vg_centos6/root
Before resizing:

After resizing:

We can say that our root partition is now transparently using space from two physical HDDs at the same time thanks to LVM.
Can I also shrink system partitions online? Yes as long as you are able to unmount them (i.e not in use by the system at a determinate point). We will now free 6GB from our home partition:
- We unmount the mount point.
$ umount /home
- We check the file system consistency by:
$ e2fsck -f /dev/vg_centos6/home
- If the five test steps were passed, we can now shrink the LV to the desired size:
$ resize2fs /dev/mapper/vg_centos6-home 8G
Notice that the latter value refers to the final size, not the reduction itself.
- We proceed to reduce the LV:
$ lvreduce -L -6G /dev/vg_centos6/home
- And now we only have to resize the file system so it exactly fits in the new LV size:
$ resize2fs /dev/vg_centos6/home
- We can safely remount it:
$ mount /home
And that’s it! Our VG will now be 6GB larger ready to assign if in need.
In our first steps with LVM we learned how to expand and shrink LVs on the fly using our own drive remaining space or newly attached HDDs to our OS.
Moving and mirroring LVs
LVMs, due to its flexibility and scalability, is frequently used in High Availability environments (HA). This is why they also implement a set of instructions regarding data replication.
For example, let’s suppose you want to move a PV (/dev/sda2) to a newly installed SSD (/dev/sdb1). The steps would be:
-
Create a PV out of the newly installed HDD.
-
Add the PV to the existing VG with vgextend.
-
Move the old PV to the new PV:
$ pvmove /dev/sda2 /dev/sdb1
Keep in mind that this may take a while regarding your configuration
-
Unattach the old PV from the VG:
$ vgreduce vg_centos6 /dev/sda2
And by this you could safely physically remove /dev/sda2 from your machine. This is an useful and a straightforward way to migrate PVs. However, this is not the safest way to do it in critical production systems, where data i/o is always being held. It is much more recommendable to use lvconvert.
Having a mirror of your installation is almost an obligation in sensitive setups. If you want to mirror your var LV, you can achieve it under LVM by issuing:
$ lvconvert --corelog -b -m 1 /dev/vg_centos6/var /dev/sdb1
Explanation:
- The –corelog flag means that the log needed to keep the mirror in sync won’t be stored in the hard drive, and the mirror will be resynchronized in every reboot.
- -b is to launch the process in the background.
- -m stands for mirror and is followed by the number of mirrors we want to set.
- We then set the LV we want to mirror and in which PV (always belonging to the same VG).
The mirror is now set. Every little change produced in the var LV will be reproduced in /dev/sdb1. By issuing:
$ lvs -a -o+devices
we will have full knowledge of what is going on with our LV mirror:

No more need to keep the mirror? We can always detach one of its legs by:
$ lvconvert --corelog -b -m 0 /dev/vg_centos6/var /dev/sda2

And by this we would have migrated our var LV to another physical partition in the safest way we could.
And what about snapshots?
Imagine that we want a snapshot of the root partition before playing around with some critical software that could in the end break our installation. Firstly we will need to create a LV capable to host all the capacity that is already being used for the volume we are about to take a snapshot, plus all the changes that will occur while the snapshot is on. If the snapshot LV ever reaches its full capacity, the snapshot feature will be broken since it won’t be able anymore to host changes and data will become corrupted.
We are going to create a 15GB snapshot LV of the root LV:
$ lvcreate -L15G -s -n rootsnapshotYYYYMMDD_HHMM /dev/vg_centos6/root

This newly created LV will increase its Data% capacity in consonance with the LV that is under snapshot. So, for example, if we create a 3GB file in the root LV, we will have:
$ cd root && dd if=/dev/zero of=large.file bs=1024 count=3M

The snapshot capacity in order to host changes produced has decreased a 20% due to this 3GB file in the root LV. When it reaches its maximum capacity, as said before, the data that it stores will become unusable and we won’t be able to restore the former LV to the point where the snapshot was created. If you happen to mount the LV snapshot, files will remain exactly the same as when it was created and, by this, you will always be able to restore to this original point. We can even tar the whole snapshot files so we can store backups of it in, for example, an external drive, but we can always restore a snapshot by:
$ lvconvert --merge /dev/vg_centos6/rootsnapshotYYYYMMDD_HHMM
However:

In this particular case, due to the impossibility to unmount the root LV online, we need to place a reboot. After it, the snapshot will be automatically restored and its LV will be removed. No trace of the modifications we did after setting up the snapshot. True is that the machine will be offline for a short period of time, but we will have the chance to recover a broken OS.
Snapshots shouldn’t be considered as the main backup option as they are not as reliable as a mirroring in terms of data consistency or restoring capabilities. However, they can be really useful and save us a headache in some particular scenarios. The key is to combine, know our needs and act accordingly.
Exporting and importing VGs and their configuration
You may find yourself in the need to restore your LVM configuration / layout. For example, if one of your mirrored LVs is hardware damaged and needs to be replaced, with vgcfgrestore you will be able to redraw your LVM configuration to the disk, so it is important that you previously backup your LVM metadata:

This file contains every little bit of the LVM layout of the VG configuration we exported. It is good to know that the system automatically creates these backup files under /etc/lvm/backup when doing sensitive operations with LVM, and that they are being archived in /etc/lvm/archive. So, whenever you need to rewrite the VG metadata to a PV, you can do it issuing:
$ pvcreate --uuid "ObQDtz-DuvG-SY3a-kzM9-u2Dt-TxUZ-pEweti" --restorefile /tmp/vgcfgexport.conf /dev/sdb1
and then
$ vgcfgrestore -f /tmp/vgcfgexport.conf vg_centos6
In here we are creating a PV with the same UUID of our /dev/sdb1 (supposing that its lvm metadata broke), and we are telling to restore the VG configuration we previously exported to a file. We can always know our volumes UUID from the backup configuration files.
Do not forger that vgcfgbackup|restore command only restablishes the broken lvm metadata / structure; the disks must contain by themselves the data.
VGEXPORT and VGIMPORT
Unlike vgcfgbackup|restore, which only refers to LVM metadata backup and restore, vgexport is useful if we want to export our VG to another machine. It does undo the VG without touching any of the data stored in the LVs. To do so, it is necessary to disable the VG and prepare it to exportation. We created data VG that contains two LVs in PV /dev/sdb1 and we will export it to another machine. Firstly we need to unmount the LVs and disable the VG so no data is written
$ umount /dev/data/data1 $ umount /dev/data/data2
And now we disable the VG:

And then we export the VG:
$ vgexport data
We can now physically extract the PV and attach it to the new machine. The new machine will directly recognize it:

However:

We now import the VG:
$ vgimport data
And activate it:
$ vgchange -ay data

Success! We have our VG data back, with all its files and LVs. We can mount it and work with it as if we were in our previous installation.
Conclusion
LVM is the swissknife tool regarding storage capabilities. Flexibility, scalability, solid backup feature, ease of deployment… After this brief introduction to LVM and its benefits, will you still be considering using the old HDD partitioning way? I, particularly, surely won’t.

